Thinking Backwards
Notes on the research endgame

Chess players spend a lot of time studying openings. They face a fundamental problem: the set of possible continuations increases exponentially. Even the best players only memorize so-called “book” moves up to a depth of around ten. However, as the game progresses, the number of potential endgames also decreases exponentially. Starting from a (never-before-seen) game position, players learn to reason backward toward different patterns of winning positions, recognizing sequences that result in checkmate in ten moves.
One way to understand an LLM is as a chess player who has memorized an incredible number of openings. Given any sequence of text, it knows where humans would go next. Next-token prediction by definition has no ability to reason backwards from a fixed end point. Starting from a never-before-seen prompt, the choices of the LLM have no guarantee to bring you to a desired goal.
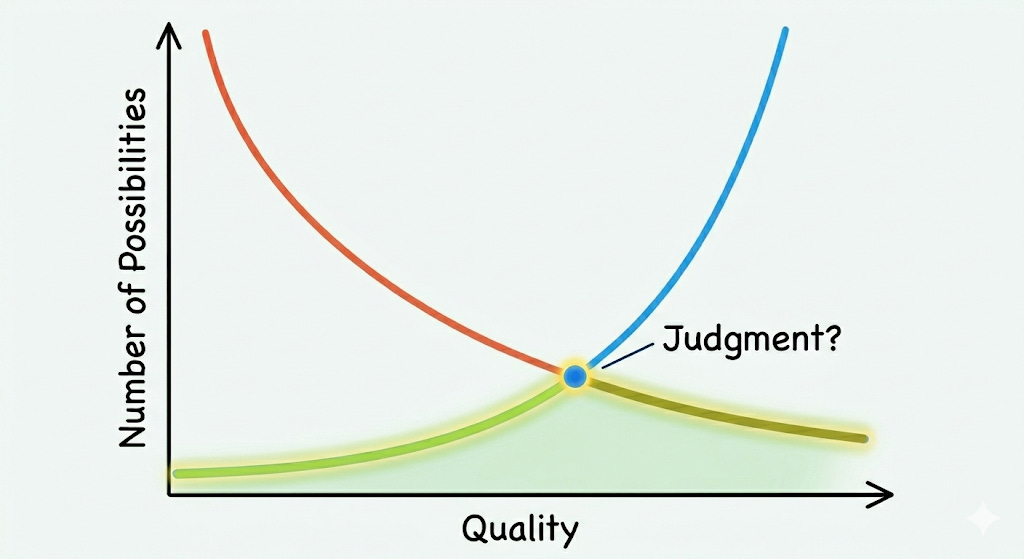
A lot of human tasks are like studying chess openings. Proofreading an essay or simplifying an algebraic expression follows known rules and sequences. But how do you write an applied microeconomics paper? First, you download and merge data, then run regressions, and then what? It depends: maybe you need to write down a model, maybe revisit the econometrics, maybe refine the research question. When you make these choices, you are thinking backwards from the aspirational introduction or abstract of the paper you would like to write. The LLM has no knowledge of when to look up from the book of openings. When no known option exists (almost all the time), it applies its own tiebreakers – what ML people call inductive biases – to keep muddling forward. Any errors along the way begin to compound. (A strong empirical regularity is that as task length increases, LLM performance degrades.) Instead, the LLM generates yet more specifications and merges additional datasets.
This problem of backward induction is the core problem with research in the age of Claude Code. This semester, I was the TF for Econ 1425, the undergraduate political economy course at Harvard, where I worked with a group of students to write what was, for many of them, their first economics paper. Almost universally, they were able to generate incredible datasets and run extremely sophisticated econometric specifications. Multiple times, I sent images of tables and figures from other papers as suggestions only to receive near-exact recreations down to the color scheme and font choices. I found, though, that as they iterated, the question itself often become more confused. Small errors with bad controls or strange log(n + x) transformations compounded. Rather than working toward a cohesive paper, the LLM suggests that we create Online Appendix C, D, and F (ironically creating something that looks more like a job-market paper than AER: Insights).
To be concrete (I will combine examples here for anonymity), often the project would start with a simple relationship – the effect of immigration on political polarization or religiosity on conflict. Then, of course, one wants to add data on unemployment, social capital, and everything you can get from Raj Chetty’s website. The LLM makes it even easier to run infinitely many permutations of these specifications, to look at how the effect appears stronger in certain subgroups, how the first stage seems weaker with and without certain sets of controls. It seems to have a special love for saturating the model with as many fixed effects as possible in a drive toward some notion of causality. Of course, when you do that, very little variation remains and the intuitive relationships we found disappear. In a strange inverse of p-hacking, people seemed to lose the big picture, preferring to give up entirely.
In contrast, not once did anyone propose a model to generate predictions consistent with the results. To do so, you would need to imagine the structures that could have generated the empirical pattern. The model requires you to go backwards from the empirical regularities toward an overarching structure. A good model becomes more parsimonious as the explanatory power increases. This is difficult for humans and seems extremely challenging for LLMs.
This is not just a problem with economics or transformer-based models. Machine learning in general excels at prediction but largely fails to generate compelling theories. As Sendhil and Ashesh point out, while AlphaFold was perhaps the greatest advancement in machine learning over the past decade, it has not generated a single new theory in biology or chemistry. Exactly the opposite: it leveraged our pre-existing theories of the relationship between proteins to generate novel and accurate predictions. Economics could certainly benefit from higher explanatory power and better predictions. But when asked about great insights from economics, I doubt most would think of papers with high R² values. Instead, we’d think of heuristics like opportunity cost or adverse selection. These ideas give generalizable, portable predictions and intuition in many domains. They are also exactly what is missing from the LLM.

Imagine you could train an LLM on the corpus of all papers published in the top-five economics journals. The model understands the latent space of well-published existing ideas. When you present it with your new project – hopefully, a sequence of ideas and choices it has never seen before – it will fill them in a way that resembles already-published papers. But this is precisely the problem: the QJE is not in the business of publishing papers that fill gaps in the literature. (Even Econometrica won’t want to just publish your new proof for Lemma 5 from their last issue.) It is exactly the selection of a point outside of the distribution, and the process by which you infer the steps needed to get there, which is what you need to learn to do.
To identify that outside point and figure out how to get there, you need to explore and ideate. The LLM is an ideal partner to do just that. That we can now iterate much more quickly and get more shots on goal is an amazing thing. But without that outside point guiding you, the inductive bias of the LLM will keep guiding you further into the interior of the latent space of published work, further into the robustness checks and latest empirical methods. We prize good mentors precisely for their ability to pull us out of this trap. They help outline the path toward the unknown, guided by what we call “judgment” or “taste”.
How to develop a sense of judgment is a hard problem, and I won’t be the first to not solve it. What I do know is that it is increasingly easy to not develop any such quality. It is a lot more fun to push AI agents to try other interesting empirical specifications or check new data than it is to spend effort thinking about what your idea really is. I have spent way more time this term chasing rabbit holes and creating nice-looking plots than writing clear introductions or outlines of what I want to do. Clearly delineating my comparative advantage over the AI is helpful in pushing back against that. Concretely, I am trying to benchmark my progress on the basis of conceptual rather than data-specific progress and deliberately taking time to simplify LLM-assisted empirical work and rewrite aspirational introductions.
Knowing how to work backwards from the final output is easier than knowing when to do so. Chess experts regard just four or five moves each game as “critical moves” where everything hangs in the balance. Watching a game, it can feel completely random which moves take just seconds and which will have them spend half their time calculating potential futures. By the time I realize the importance of the moment, the game is already over.
Thanks to Can, Cameron, Benji, Josh, Julien, and Bek for helpful conversations that sharpened the ideas in this post.
Really good post Leo. "I have spent way more time this term chasing rabbit holes and creating nice-looking plots than writing clear introductions or outlines of what I want to do" is something I can relate to a lot over the last several months. While the LLMs and "AI scientists" are effective at processing data and parsing literature, they frequently miss the "critical moves" that would drive meaningful conceptual advances.
Is the average human scientist or researcher better at this? Since so much of the grad school process is oriented toward publishing in major journals, I often find myself mimicking the experimental architecture of other papers I admire. I imagine that truly ground-breaking research requires breaking out of this trap--I guess that's something to aspire to.